25 min read 3 hour project ~$100 Medium
Overview
If you’re training LLMs, building AI apps, or developing agents - you’ll need some way to evaluate their performance. This can come at different points in the development lifecycle: during initial development, as it’s in production to detect regressions or drift, or as you seek to upgrade to newer models and/or configurations. Because the outputs of LLMs, AI apps, and agents are typically subjective or open-ended, there are essentially only three ways performance can be measured:- Human data labeling
- Real user feedback
- LLM-as-a-judge
- ✨ Vibes ✨
The Goal
We’re really going to nerd out on this one: our task today is to determine which open-source model family is best at creating ELI5 explanations of paper abstracts from the pre-print server Arxiv. ELI5 stands for “Explain Like I’m 5”, popularized by the now-defunct dataset ELI5 from Facebook. This task may seem trivial, but it’s a great demonstration of LLM-as-a-judge for a few reasons:- It requires high-level world-knowledge and understanding of complex technical concepts
- It requires the ability to map a high-level concept to a low-level explanation and communicate it effectively
- It’s extremely subjective, so there is no realistic way a ground-truth label set can be created
Getting the data
We’ll grab the current snapshot of the Arxiv metadata from Kaggle and sample 100,000 rows.Explore the data
Explore the data
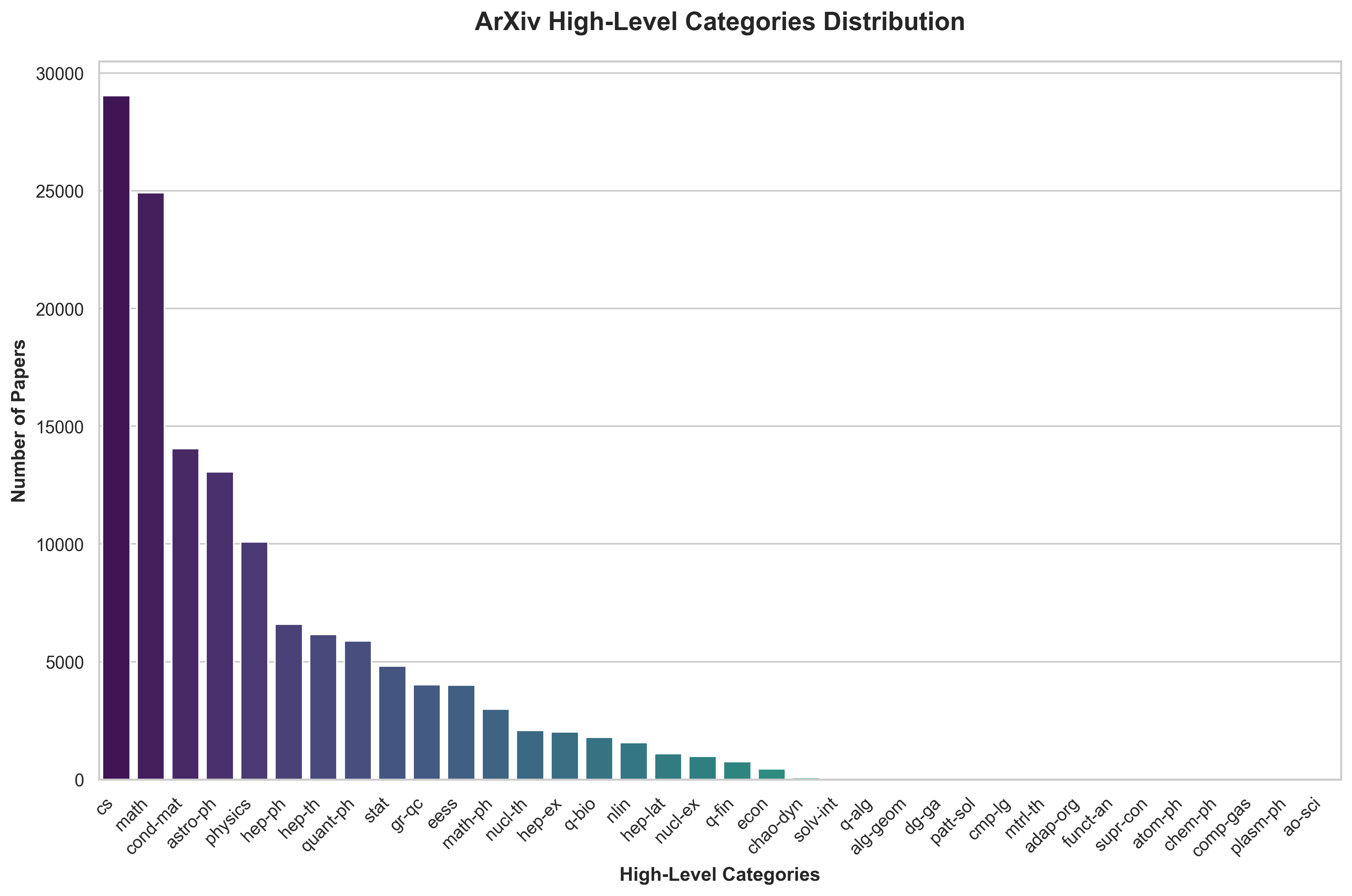 As you can see most of the high-level categories are computer science, math, and physics - with a long-tail of other more esoteric categories.
As you can see most of the high-level categories are computer science, math, and physics - with a long-tail of other more esoteric categories.
Generating the explanations
As of this writing, we serve 4 model “families” on the Sutro platform: Llama, Qwen, Gemma, and GPT-OSS. So, we’ll use smaller or medium-sized variants of each model family for the explanations, and their larger counterparts for the evaluations. It’s incredibly simple to generate the explanations using the Sutro SDK. For a sanity check, we’ll run the first 1000 rows through each model using protoptying (p0) jobs.
 An example result from GPT-OSS 20B looks like this:
Input Arxiv Abstract:
An example result from GPT-OSS 20B looks like this:
Input Arxiv Abstract:
We report an experimental design where the position and resonance frequency of the Nitrogen Vacancy (NV) in a diamond are correlated with the room temperature. A simple model trained on the interpolated correlation data predicts both quantities. The predictive tracking of the NV's location enables continuous operation of the NV quantum computer under ambient conditions for a week without recalibration.
Output ELI5 Explanation:
We did a test to see how a tiny thing in a diamond moves and makes a special sound when the room is warm. We made a smart guess that tells us where it is and how it sounds. This lets a tiny computer in the diamond keep working all week without having to fix it.
Scaling to the 100,000 row sample is as simple as removing the slicing of the dataframe, and setting the job priority to 1.
| Model | Duration | Input Tokens | Output Tokens | Cost |
|---|---|---|---|---|
| Llama 3.1 8B | 35 minutes | 27M | 16.3M | $1.03 |
| Qwen 3 14B | 48 minutes | 25.4M | 11.9M | $5.76 |
| Gemma 3 12B IT | 35 minutes | 24.1M | 18.8M | $9.16 |
| GPT-OSS 20B | 30 minutes | 29.5M | 25.8M | $1.03 |
Evaluating the explanations
As mentioned earlier, it’s likely that larger models will be better at evaluating the explanations. This is because they contain more world knowledge and have more free parameters with which to reason. In some cases, you may have a “trusted” model that you want to use for all evaluations. But in this, case how do we know which model is the best judge? And how do we know the larger model in a specific family won’t be biased towards its smaller sibling due to similarities in the underlying training data? To combat these biases, we’ll use a larger model from each of the four families to evaluate the explanations from the three smaller models. Consequentially, this means that each smaller model will be evaluated by three larger models from other families. In traditional ML, this is known as ensemble modeling - using the responses of multiple models to make a single prediction.Pull down the results and append them to the original dataframe
Pull down the results and append them to the original dataframe
Plot the results in a heatmap
Plot the results in a heatmap
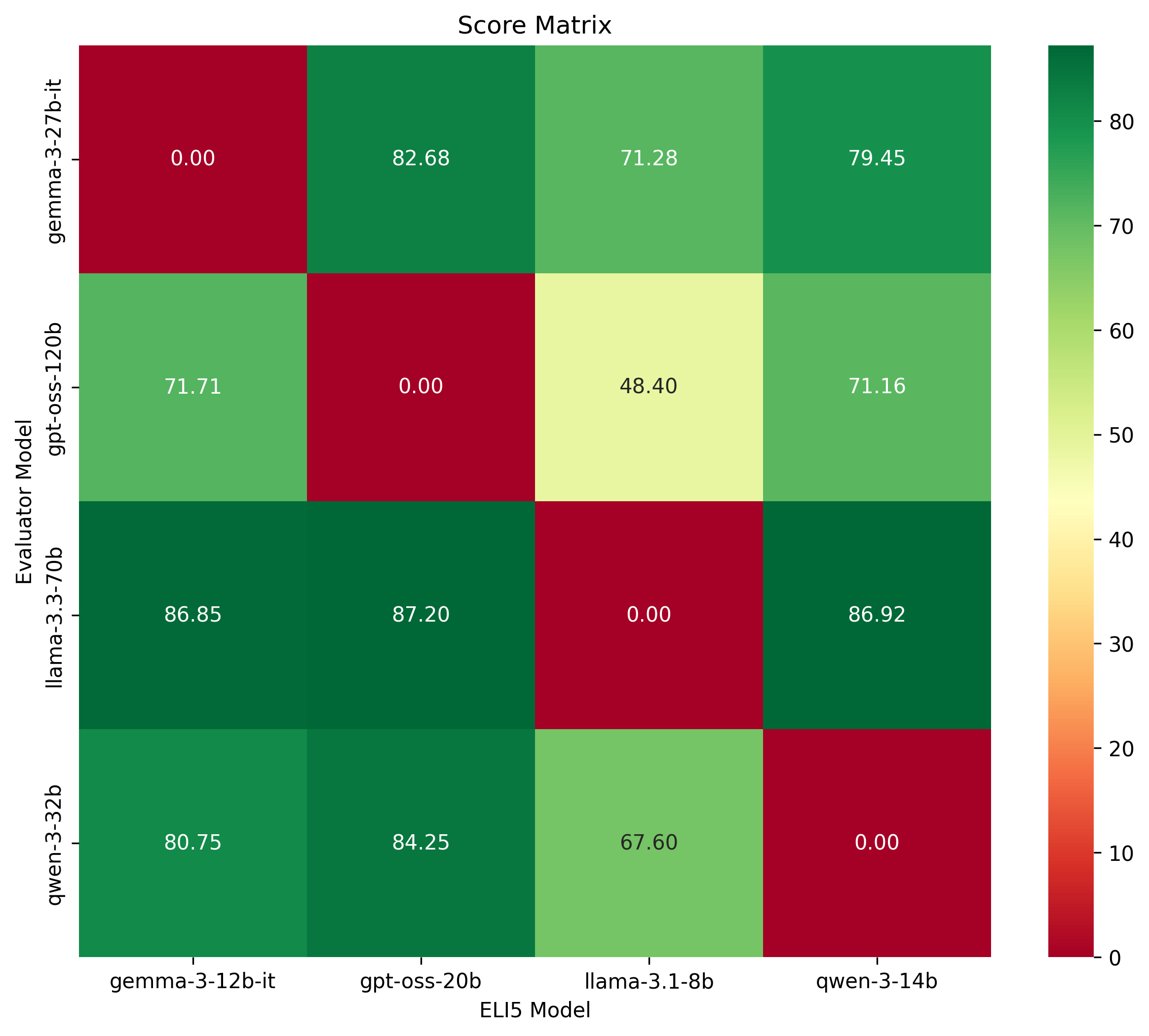 These are interesting and revealing results. We can see that the GPT-OSS 20B model has the strongest overall performance as reviewed by the three larger models in other families. The GPT-OSS 120B model is the also the harshest evaluator, giving the lowest scores to the other model families.
The situation is inverted for the Llama models, where Llama 3.1 8B is the weakest performing model as reviewed by the three larger models in other families, yet Llama 3.3 70B is the most generous evaluator of the other model families.
We already likely have our answer: GPT-OSS 20B is the best model for this task of the models we evaluated. At this point, we could move onto another set of evals to optimize our prompt, sampling parameters, or structured output schema. Instead, we’ll run one more set of evals to confirm our hypothesis.
These are interesting and revealing results. We can see that the GPT-OSS 20B model has the strongest overall performance as reviewed by the three larger models in other families. The GPT-OSS 120B model is the also the harshest evaluator, giving the lowest scores to the other model families.
The situation is inverted for the Llama models, where Llama 3.1 8B is the weakest performing model as reviewed by the three larger models in other families, yet Llama 3.3 70B is the most generous evaluator of the other model families.
We already likely have our answer: GPT-OSS 20B is the best model for this task of the models we evaluated. At this point, we could move onto another set of evals to optimize our prompt, sampling parameters, or structured output schema. Instead, we’ll run one more set of evals to confirm our hypothesis.
Using relative (ranking-based) evaluations
In our previous evals, we used larger models to evaluate the ELI5 explanations in isolation: just showing the abstract and the explanation to the evaluator model and asking it to score the explanation on a scale of 0 to 100. But since we’re trying to understand which model is best for our task, it makes more sense to compare relative performance directly. This is where relative evaluations come in. We’ll now show each evaluator all three ELI5 explanations at once, and ask it to rank them from best to worst.Pull down the results and append them to the original dataframe
Pull down the results and append them to the original dataframe
Create the win rate percentage matrix
Create the win rate percentage matrix
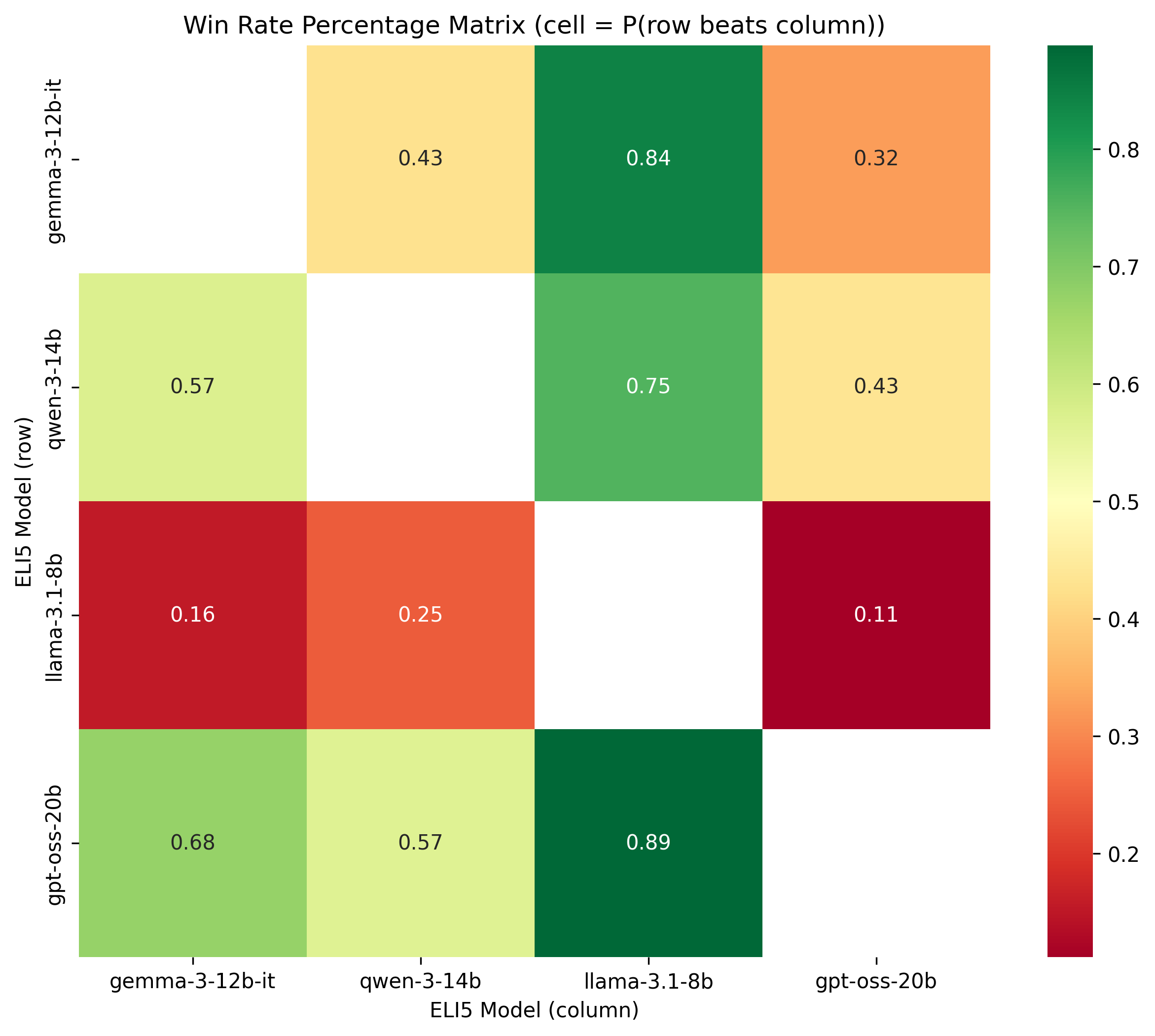 This time, we’re pooling the results of the three evaluators to determine the win rate percentage matrix. We only care about the head-to-head comparisons of the ELI5 models.
Once again, even with the context of the three evaluators, we can see that GPT-OSS 20B is hands down the best model, beating all the others in head-to-head comparisons. Llama is by far the worst, getting beaten down by the others, often by a wide margin. Almost 9/10 times the GPT-OSS 20B model beats it.
We like to think we’re fancy mathematicians here at Sutro, so we’ll finally use the Elo rating system to determine the best model. This is often used for human skill ratings in games like chess, and more recently to rank responses from LLMs on websites like the LM Arena Leaderboard.
This time, we’re pooling the results of the three evaluators to determine the win rate percentage matrix. We only care about the head-to-head comparisons of the ELI5 models.
Once again, even with the context of the three evaluators, we can see that GPT-OSS 20B is hands down the best model, beating all the others in head-to-head comparisons. Llama is by far the worst, getting beaten down by the others, often by a wide margin. Almost 9/10 times the GPT-OSS 20B model beats it.
We like to think we’re fancy mathematicians here at Sutro, so we’ll finally use the Elo rating system to determine the best model. This is often used for human skill ratings in games like chess, and more recently to rank responses from LLMs on websites like the LM Arena Leaderboard.
Use the Elo rating system to determine the best model
Use the Elo rating system to determine the best model
| elo | wins | losses | matches | |
|---|---|---|---|---|
| gpt-oss-20b | 1629.77 | 425974 | 174028 | 600001 |
| qwen-3-14b | 1554.52 | 351422 | 248580 | 600001 |
| gemma-3-12b-it | 1523.23 | 319396 | 280606 | 600003 |
| llama-3.1-8b | 1292.47 | 103212 | 496790 | 600001 |
Conclusion
We just demonstrated how you can use Sutro to run model task evals. Our approach avoided the need for human feedback altogether, instead using an ensemble of LLMs to evaluate our task and remove the biases of any single model. This avoided the need for human labelers, or any online human feedback. We bootstrapped the evaluation process entirely offline:- in just a few hours
- on 100,000 samples, across 4 models and 16 evaluation jobs (but could be scaled to millions of samples and billions of tokens)
- for around 100 dollars
- without the need for any custom infrastructure or GPU setup
- using only the Sutro SDK and open-source Python tools
Next Steps
While we identified a good base model to start with, a good next step might be to use our winning model, and run further offline evals to improve prompts, sampling parameters, or structured output schemas - taking our task specification to a truly optimized state. And to reiterate once more - this iterative, offline eval process can be used to improve nearly any AI application or agent, including but not limited to:New model development and benchmarking:
You can continuously run large scale evals as you post-train, fine-tune, and improve your models without human feedback.Task specialization:
When trying to optimize an LLM task such as summarization, classification, or code-generation, you can evaluate your choice of model, prompt, sampling parameters, and more to optimize selections and maximize performance.Application and agent development/tuning:
As you create more complex, compound, and agentic tasks, you can evaluate entire reasoning traces, workflow outputs, and application logs to tune performance without the need for human feedback. Hopefully this helps get you started with LLM-as-a-judge methods on the Sutro platform. We encourage you to bring your own approaches, and get creative with the task you’re trying to evaluate. If you need any help getting started, contact us at [email protected]. You can review the full, resulting MIT-licensed dataset associated with this guide here:References
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena: https://arxiv.org/abs/2306.05685