10 min read ~1.5 hour project ~$2 Beginner
This example demonstrates how you can can quickly, easily, and inexpensively generate synthetic data using the Sutro Python SDK.
The Goal
Our goal today will be to generate a dataset of 20,000 high-quality, synthetic product reviews. This could be useful for:- Training/evaluating sentiment analysis models, recommendation systems, spam classifiers, and other machine learning models
- Market research simulations, A/B testing, customer segmentation
- … and more!
- Start by generating a basic dataset of 100 product reviews.
- Add structure and randomness (diversity) to the reviews.
- Add representation to the reviews, so that they are representative of underlying real-world data.
- Scale up to 20,000 reviews, seamlessly and inexpensively.
Baby Steps
First, make sure you have the Sutro Python SDK installed. This will include all dependencies required for the examples. Let’s start by creating a basic dataset of 100 product reviews.p0) job, this should take a few minutes to run. You should see something like the following when you run the job. It should take a a couple of minutes to run (GIF sped up for brevity):
 Once it’s done running, we can inspect the results in the Sutro Web UI:
Once it’s done running, we can inspect the results in the Sutro Web UI:
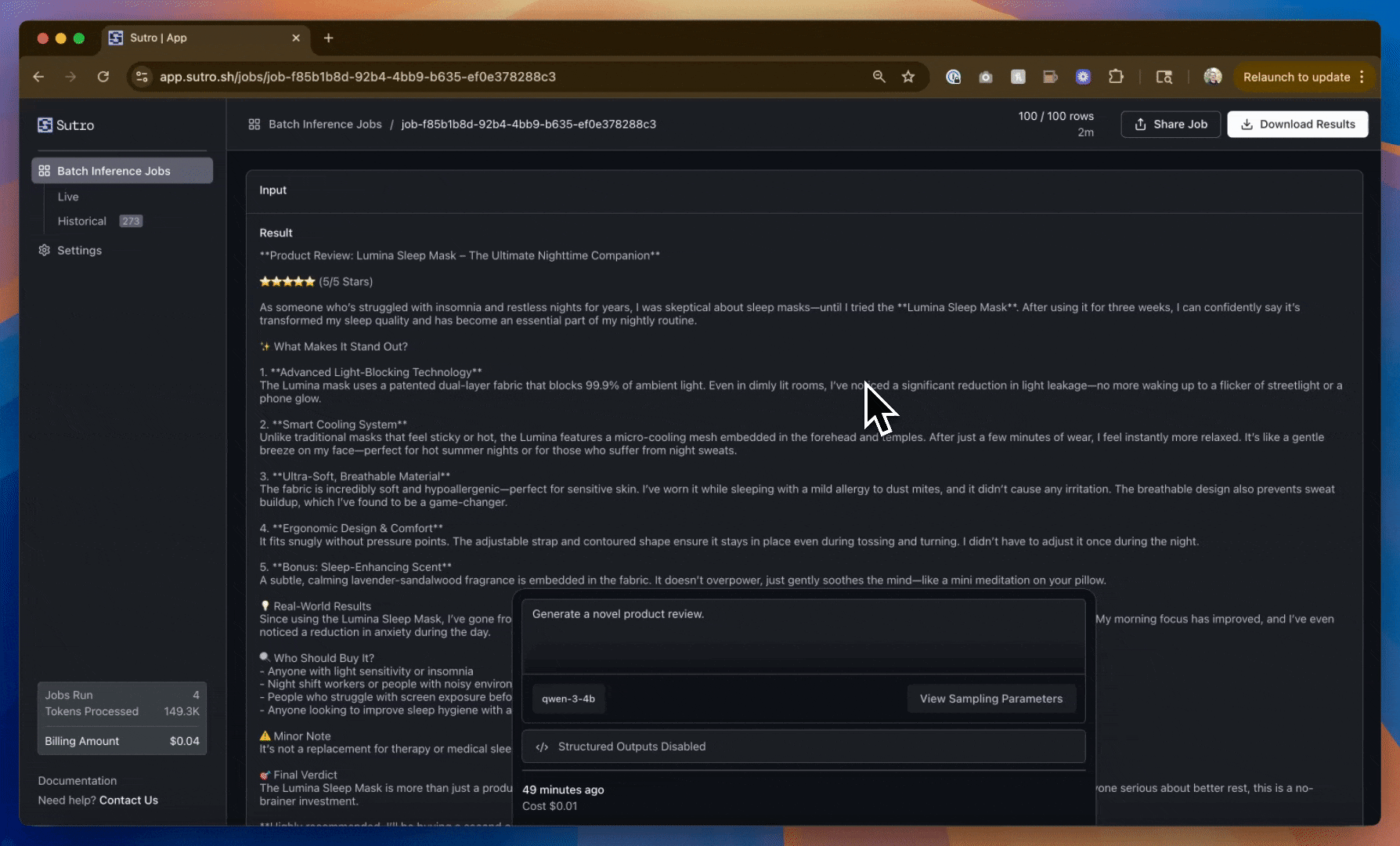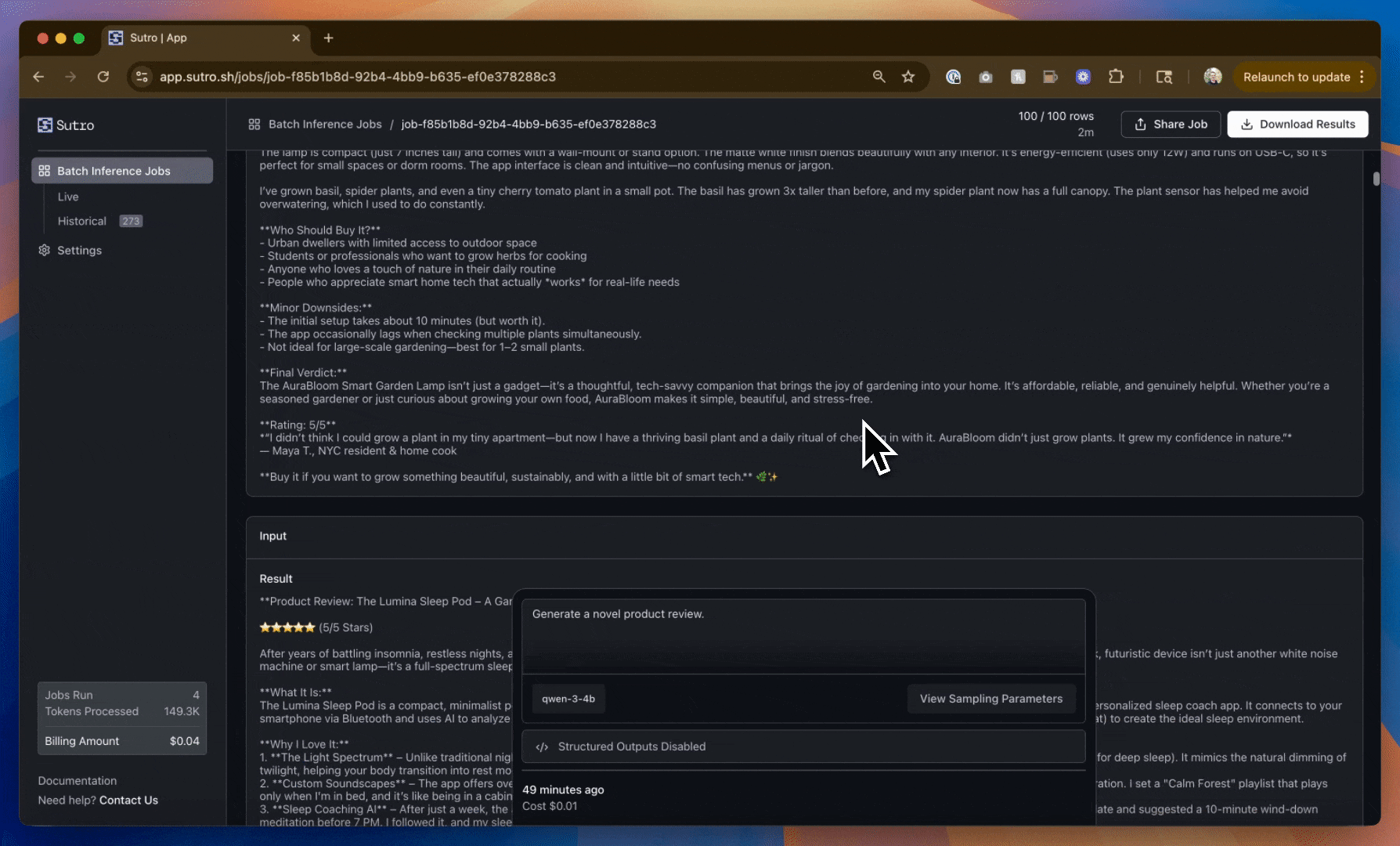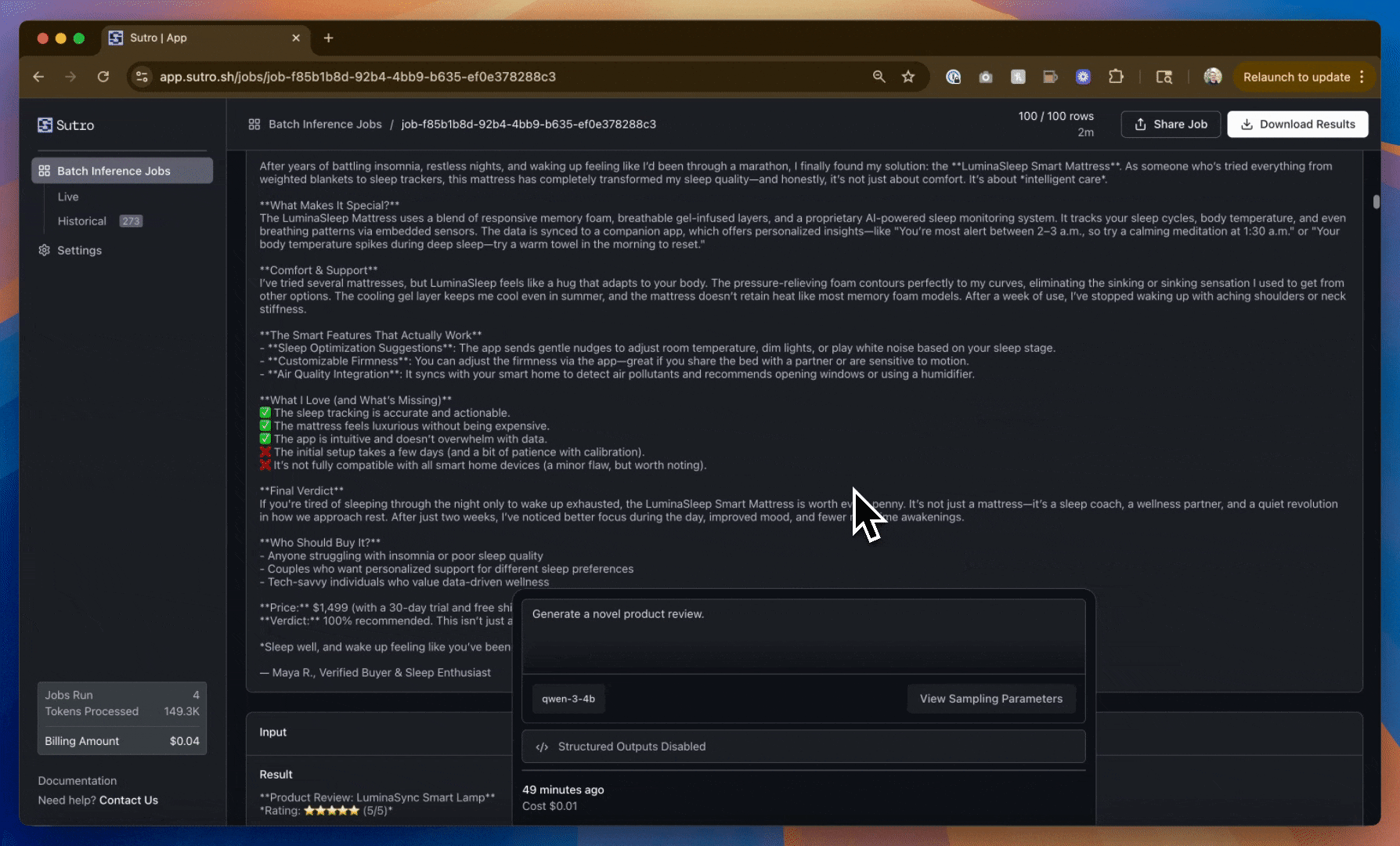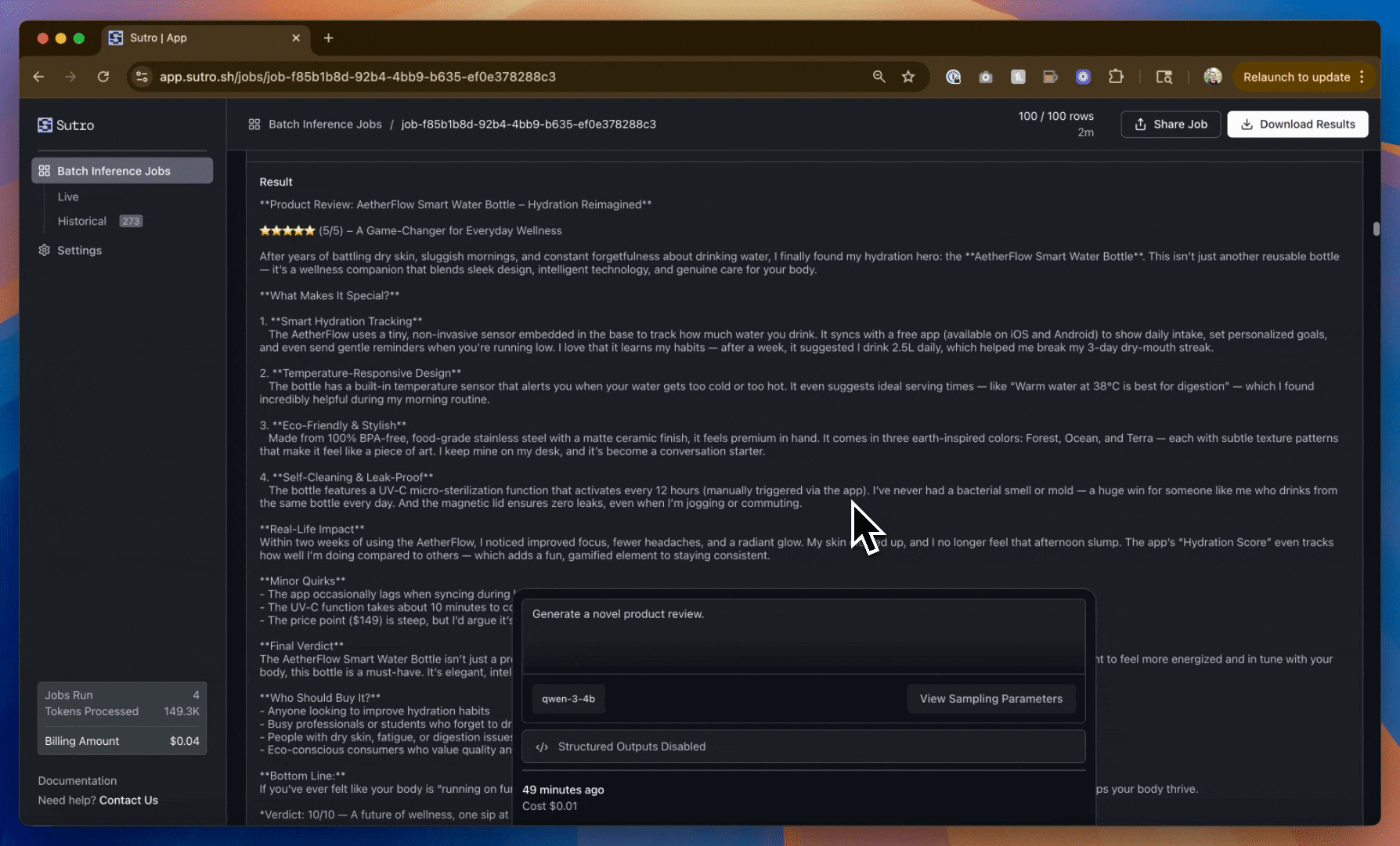 As you can see, we have data - but it’s not very useful (at least not yet)! We have far too much commonality between the product reviews including the type of product being reviewed, the rating, sentiment, and more.
This can generally be expected from an LLM until we introduce further steps for obtaining structure, heterogeneity and representativeness. So, let’s do that next.
As you can see, we have data - but it’s not very useful (at least not yet)! We have far too much commonality between the product reviews including the type of product being reviewed, the rating, sentiment, and more.
This can generally be expected from an LLM until we introduce further steps for obtaining structure, heterogeneity and representativeness. So, let’s do that next.
Let’s Walk - Adding Structure & Randomness
To begin, let’s see if we can introduce some more diversity and structure into our reviews. We’ll do this in a few ways:- Update the system prompt to include specific fields.
- Add a random numerical seed to the each of the inputs to increase diversity.
- Modify the
temperaturesampling parameter to increase randomness. - Add a Pydantic model to enforce a schema structure of the reviews we want to generate.
- Increase the model size from
qwen-3-4btoqwen-3-14bto sample from more world knowledge.
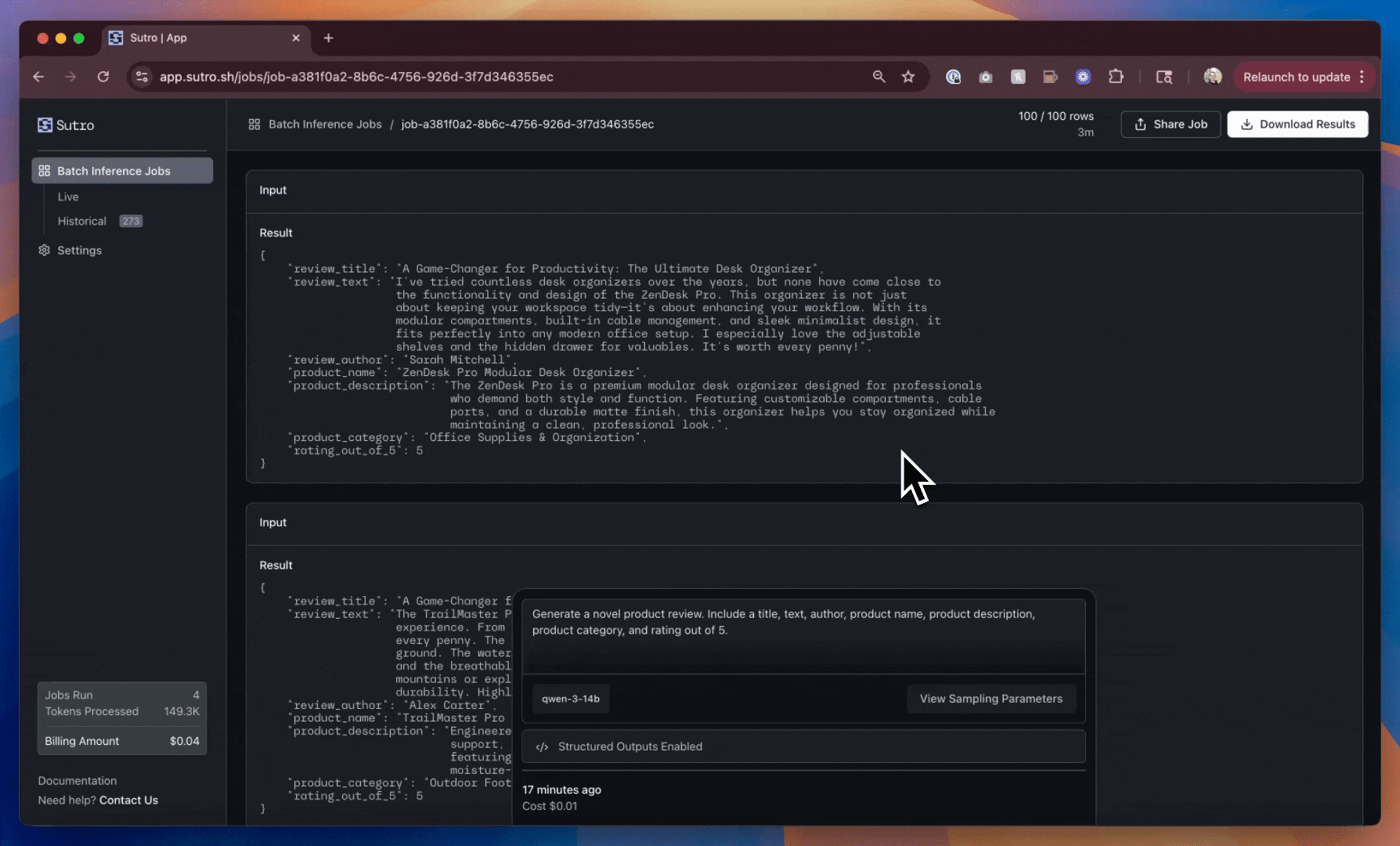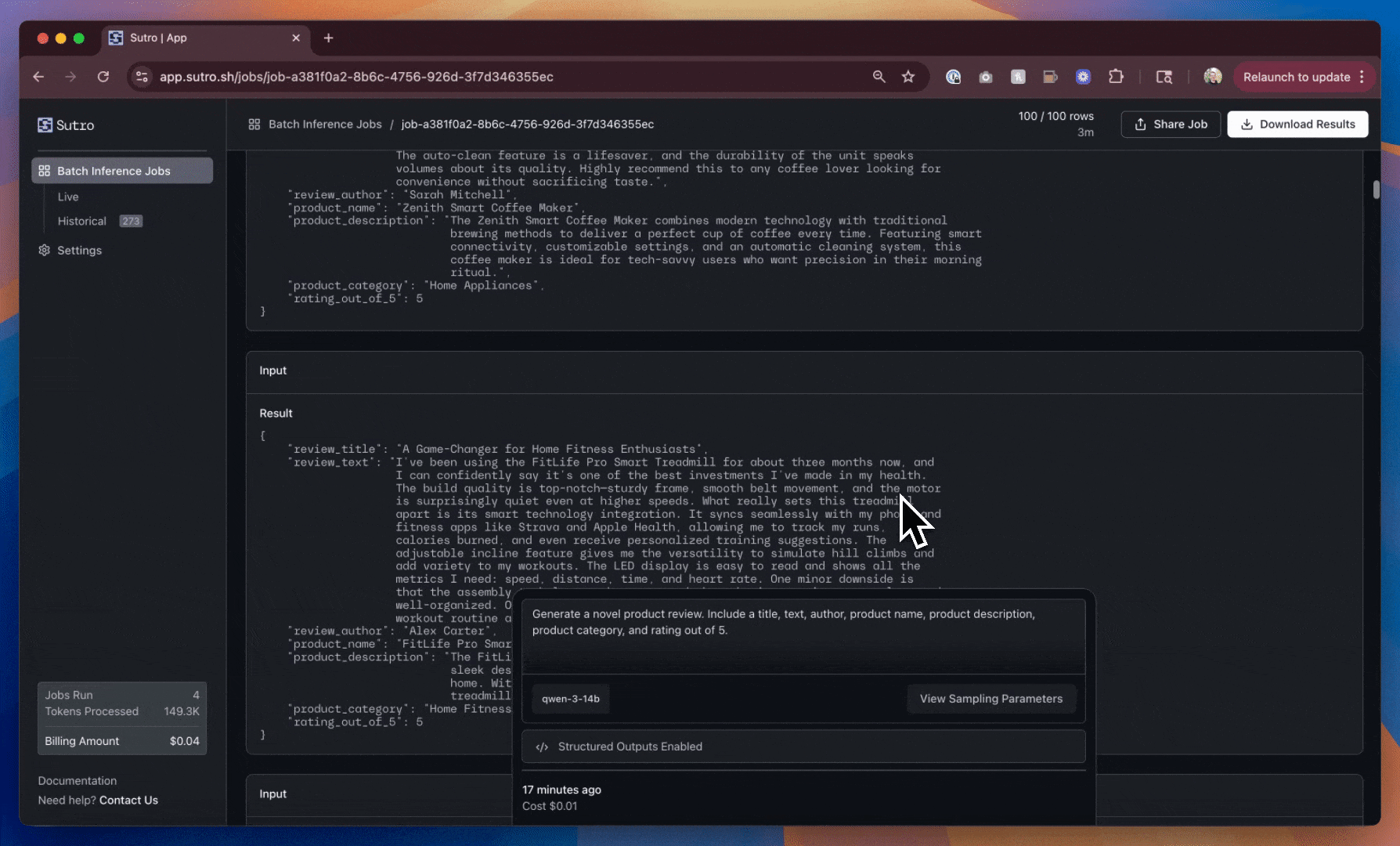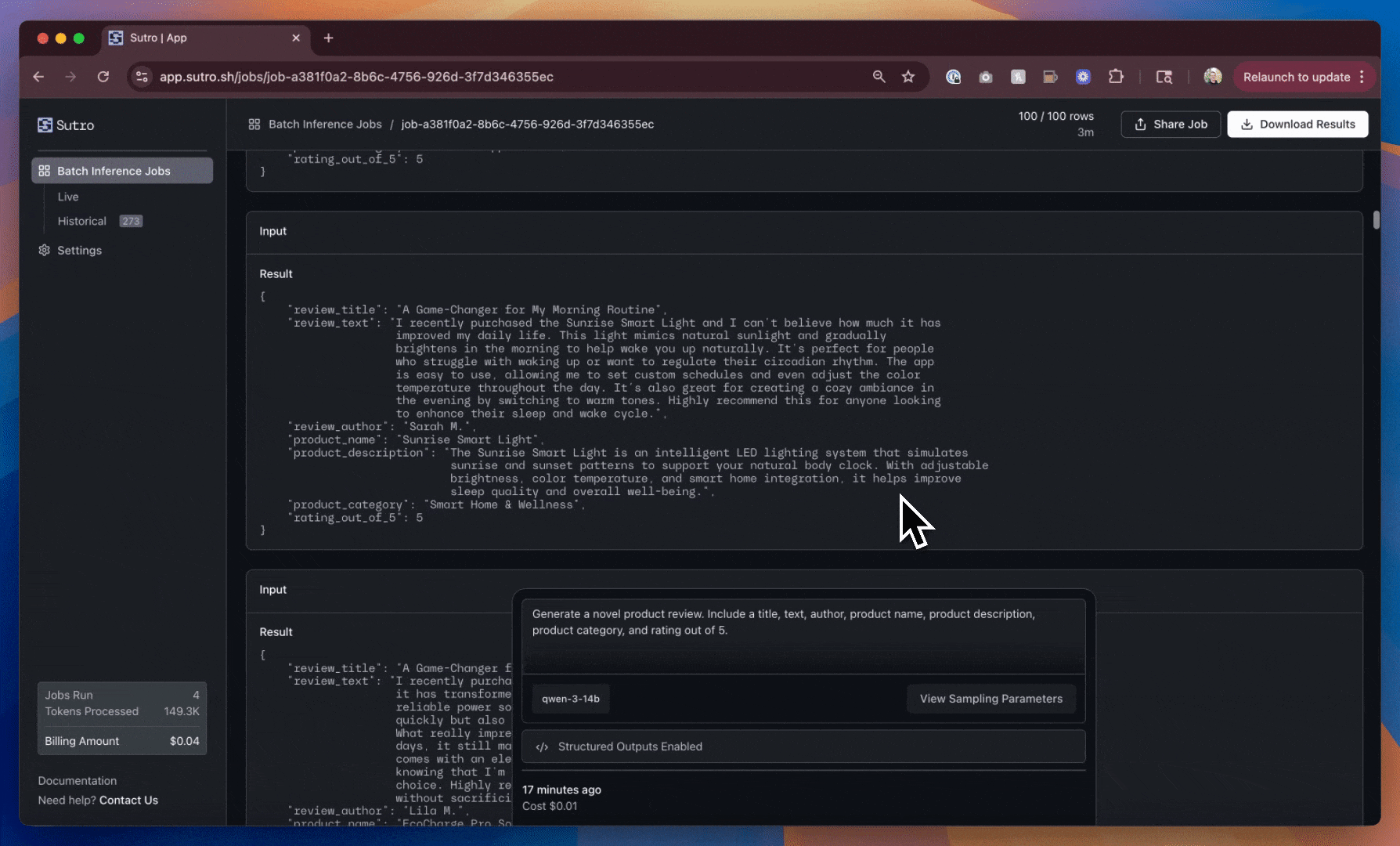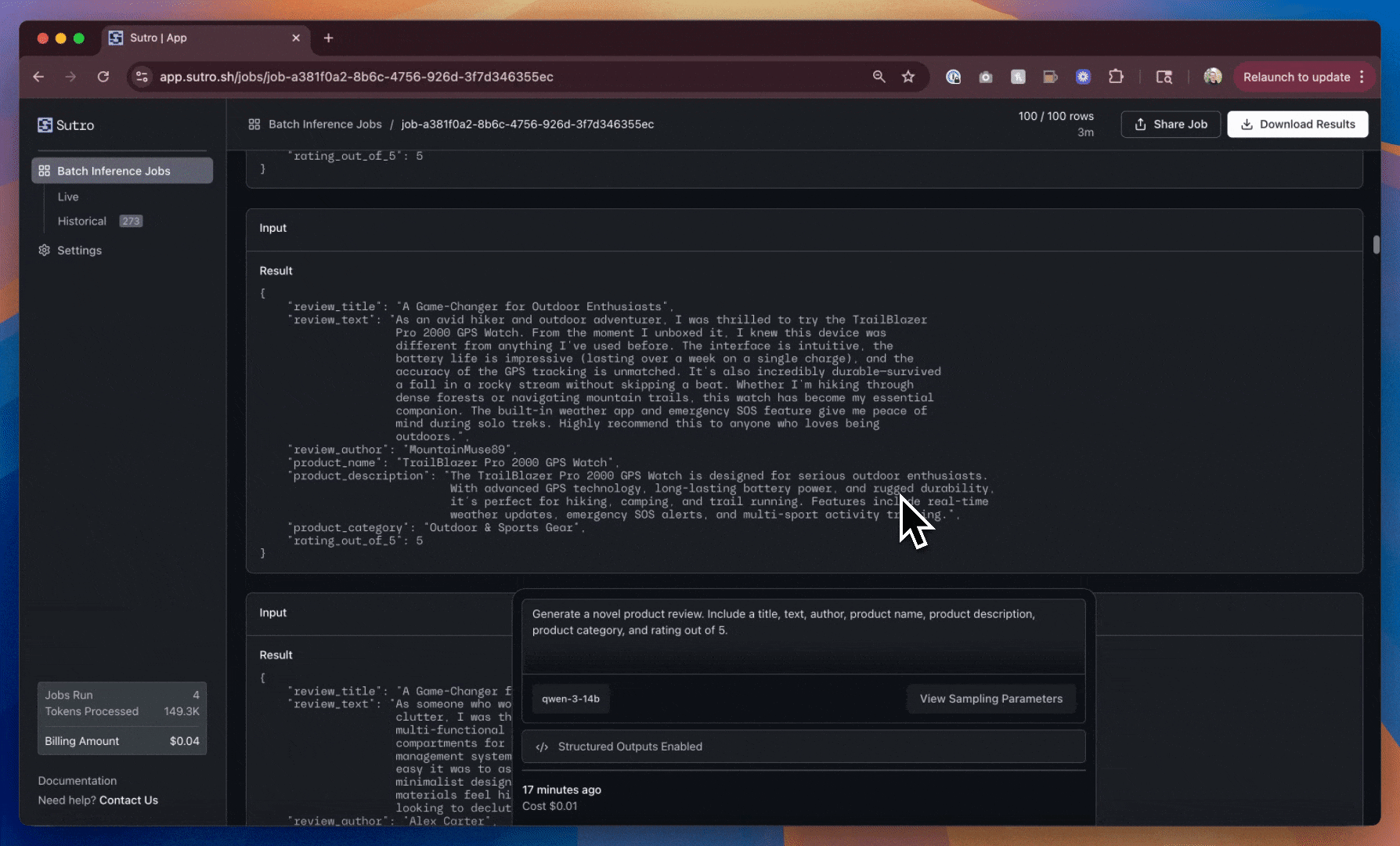 This is a significant improvement! We now have more product diversity overall, and a consistent schema for the reviews we’ve generated.
However, we can still do better. The review titles, product names/descriptions, author names, and ratings are still very similar across the reviews we’ve generated.
This is a significant improvement! We now have more product diversity overall, and a consistent schema for the reviews we’ve generated.
However, we can still do better. The review titles, product names/descriptions, author names, and ratings are still very similar across the reviews we’ve generated.
Time to Run - Adding Representation
For most valuable use cases, we want a final dataset that is representative of real-world data. To achieve this, we not only want diversity itself, but rather diversity that adheres to the real-world distribution of the data we’re trying to represent. There are various levels of complexity to achieve this, but for this example we’ll take a simple approach by using two other “seed” datasets to produce the representation we’re looking for. In our example, we’re creating product reviews, so we probably need a set of products to review, right? In the real world, perhaps if you’re running an e-commerce business you’d want to use your own product dataset for this. However, for our toy example, we’ll use an Amazon Products sample dataset from Hugging Face. It works well for our purposes - it contains 33,000 products with associated product names, descriptions, and prices.
This will certainly help us get more product representation, but how about reviewer representation? For that, we can use a personas dataset, in this case our very own Synthetic Humans 50k dataset.
This dataset contains 50,000 personas sampled from actual US demographics, and contains qualitative descriptions of each persona.
For this example, let’s say we want to generate product reviews from 18-30 year olds living in popular US cities over all of the products in the Amazon Products dataset.
To do this, we’ll need to merge the two datasets, sampling a random persona for each product. We’ll then run our previous inference job over the merged dataset. Let’s do that now.
 Much, much better! We now have a wide array of products and reviewers, faithful to our underlying real-world data. We even see cases where the rating is lower because of the mismatch between the product and reviewer demographics.
Now, let’s scale up our example to 20,000 product reviews!
Much, much better! We now have a wide array of products and reviewers, faithful to our underlying real-world data. We even see cases where the rating is lower because of the mismatch between the product and reviewer demographics.
Now, let’s scale up our example to 20,000 product reviews!
Scaling Up
To scale up to our 20,000 product reviews, it’s dead simple! We just need to make a couple of changes to our code above.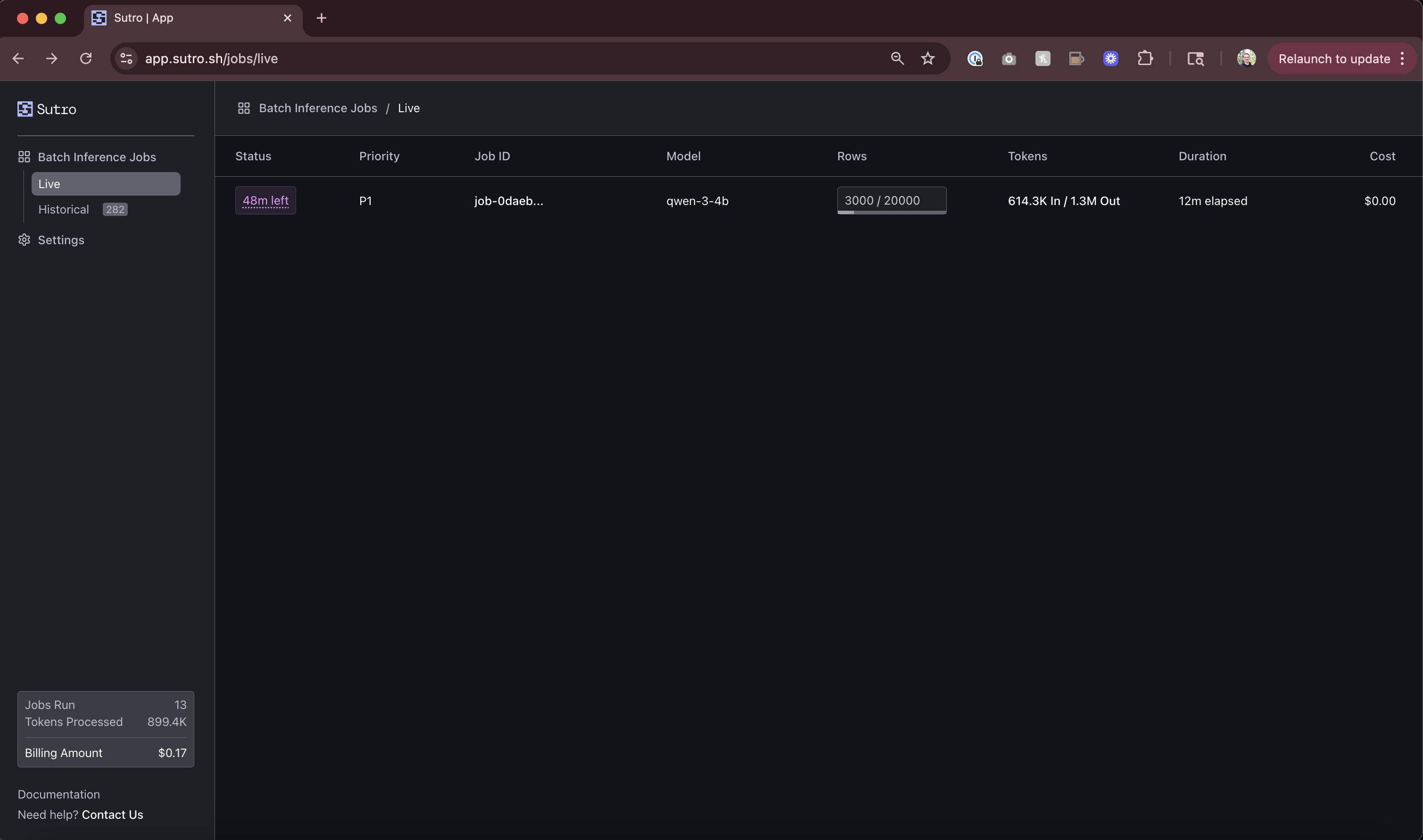 In this case, it took 29 minutes to run, and cost only $1.88 using Sutro!
Once it’s done running, you can grab the results using the SDK, or download the results directly from the Web UI.
In this case, it took 29 minutes to run, and cost only $1.88 using Sutro!
Once it’s done running, you can grab the results using the SDK, or download the results directly from the Web UI.
Recap
In this example, we demonstrated how you can easily create synthetic data with LLMs using the Sutro Python SDK. Our final 20,000 product review dataset:✅ Created using a few dozen lines of code.
✅ Representative of our underlying real-world data.
✅ Required zero infrastructure setup.
✅ In less than an hour.
✅ For less than $2!
With the Sutro Python SDK, you can easily create synthetic data with LLMs for your own use cases. Try it out today by requesting access to Sutro!
Addendum
If you want to generate even more variations, you can set then sampling parameter, which will produce n samples for each input.
 As you can see, this now has 5 distinct outputs, with slight variations on each review.
As you can see, this now has 5 distinct outputs, with slight variations on each review.